Easy to use
Spark Structured Streaming abstracts away complex streaming concepts such as incremental processing, checkpointing, and watermarks so that you can build streaming applications and pipelines without learning any new concepts or tools.
.readStream
.select($"value".cast("string").alias("jsonData"))
.select(from_json($"jsonData",jsonSchema).alias("payload"))
.writeStream
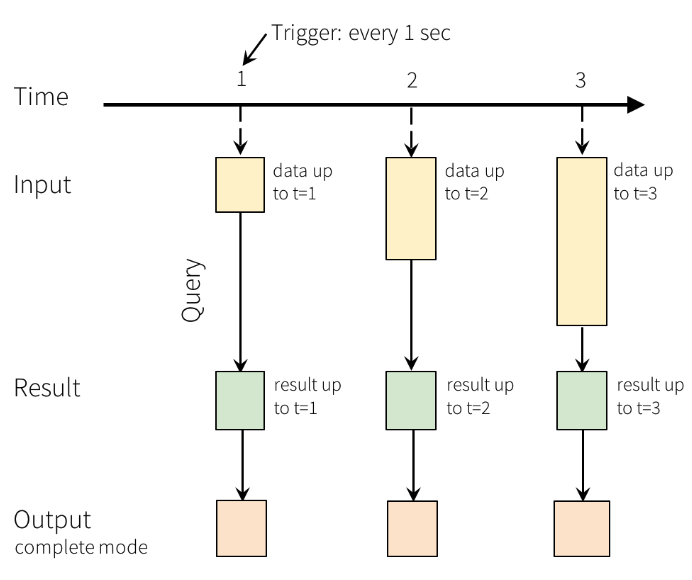
.trigger("1 seconds")
.start()
Unified batch and streaming APIs
Spark Structured Streaming provides the same structured APIs (DataFrames and Datasets) as Spark so that you don’t need to develop on or maintain two different technology stacks for batch and streaming. In addition, unified APIs make it easy to migrate your existing batch Spark jobs to streaming jobs.

Low latency and cost effective
Spark Structured Streaming uses the same underlying architecture as Spark so that you can take advantage of all the performance and cost optimizations built into the Spark engine. With Spark Structured Streaming, you can build low latency streaming applications and pipelines cost effectively.
Getting started
To get started with Spark Structured Streaming:
- Download Spark. It includes Structured Streaming as a module.
- Read the Spark Structured Streaming programming guide, which includes programming models, tutorials, configurations, etc.
Community
Spark Structured Streaming is developed as part of Apache Spark. It thus gets tested and updated with each Spark release.
If you have questions about the system, ask on the Spark mailing lists.
The Spark Structured Streaming developers welcome contributions. If you'd like to help out, read how to contribute to Spark, and send us a patch!
Latest News
- Spark 3.4.3 released (Apr 18, 2024)
- Spark 3.5.1 released (Feb 23, 2024)
- Spark 3.3.4 released (Dec 16, 2023)
- Spark 3.4.2 released (Nov 30, 2023)
